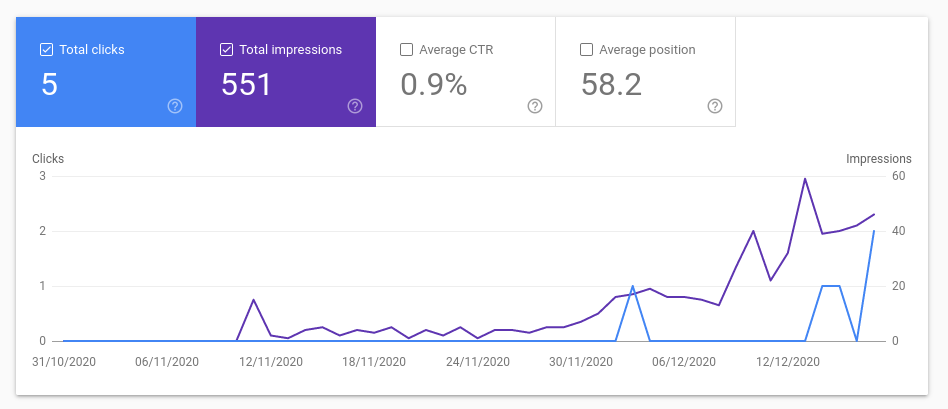
So I registered the domain name, and used the project as an excuse to learn about AWS Lambda, server-side JavaScript and Serverless Framework.
After a little while, I finished a basic bare-bones version of the app. And used it a few times, for real! Then, it sat dormant for about six months, while I spent time working on other things like blogs.
Fast-forward to November 2021. I wanted to update it. I wanted to add some new features. I looked at the old code with dread.
I’m going to have to learn JavaScript again, I thought. Who even wrote this code?! How do I deploy it to AWS again? What’s this new feature on serverless.com?
Oh dear, a long road ahead…
Hacker News-driven development
When I have something difficult to do, I like to go waste some time get some inspiration on a message board.
So I was reading this thread - “Solo-preneurs, how do you DevOps to save time?” on Hacker News (HN is actually my favourite goldmine of info and opinion from people who are actually doing this stuff for real, not just throwing up YouTube tutorials).
And someone replied with their deployment technique:
I never realised I was using spooky arcane oldhat stuff! I feel wizardly now.
My projects (for small clients and myself) basically use this.
- A “build.sh” script that does a local build of back end and front end
- A “deploy.sh” script that scp’s everything to the server (either a digital ocean VPS or an EC2 instance), runs npm install, runs database migrations and restarts with pm2
So running my entire CI pipeline in terminal is: ./build.sh && ./deploy.sh
Far away in the real world, people are still using simple tools to create things. You don’t need to use the shiny-shiny stuff. Keep it simple.
A lightbulb moment.

What does ‘simple’ look like, in my case?
For me, it probably means using tools and frameworks that I already know. Choosing boring technology. And making the build and deployment steps almost too easy. So I can focus on shipping new features quickly.
So I threw my toys out of the pram and rewrote the app in Java. Yes, Java.
Spring is the way
For me, Java is my bread-and-butter. I’m not a hardcore Java developer, but I know enough to build simple things. And in the Java world, Spring still reigns supreme. It’s a framework for building just about anything - APIs, web apps, reactive applications.
Let me convince you (I’m also talking to myself) why it’s great.
Spring has well-maintained official docs. In fact the documentation is so good, that it’s boring. There is a Javadoc page for every class and method. Every feature is described in detail, down to absolute minutiae. It’s gold. There’s also a ton of unit tests to learn from.
👍 Goodbye scouring the internet for half-baked tutorials…. hello well-written documentation.
It’s battle-tested, moves slowly and comes with batteries included. I don’t have to waste time figuring out which Node module I should use to do X or Y. (You know, that fun activity of trying to find the module that everybody else uses… the one that’s fairly stable, but hasn’t been compromised with crippling malware.)
👍 Goodbye struggling to figure out which Node packages I need… hello to everything being included in curated dependencies, with versions that work together.
Most of the big software problems have been solved, funded primarily by the deep pockets of big tech’s customers. There are patterns, examples and stable libraries. So why not just leverage all that hard work, and build something cool with it?
👍 Goodbye cobbling together a solution with Pritt-stick and toilet paper… hello to following convention-over-configuration.
So, I rewrote my entire app from scratch:
-
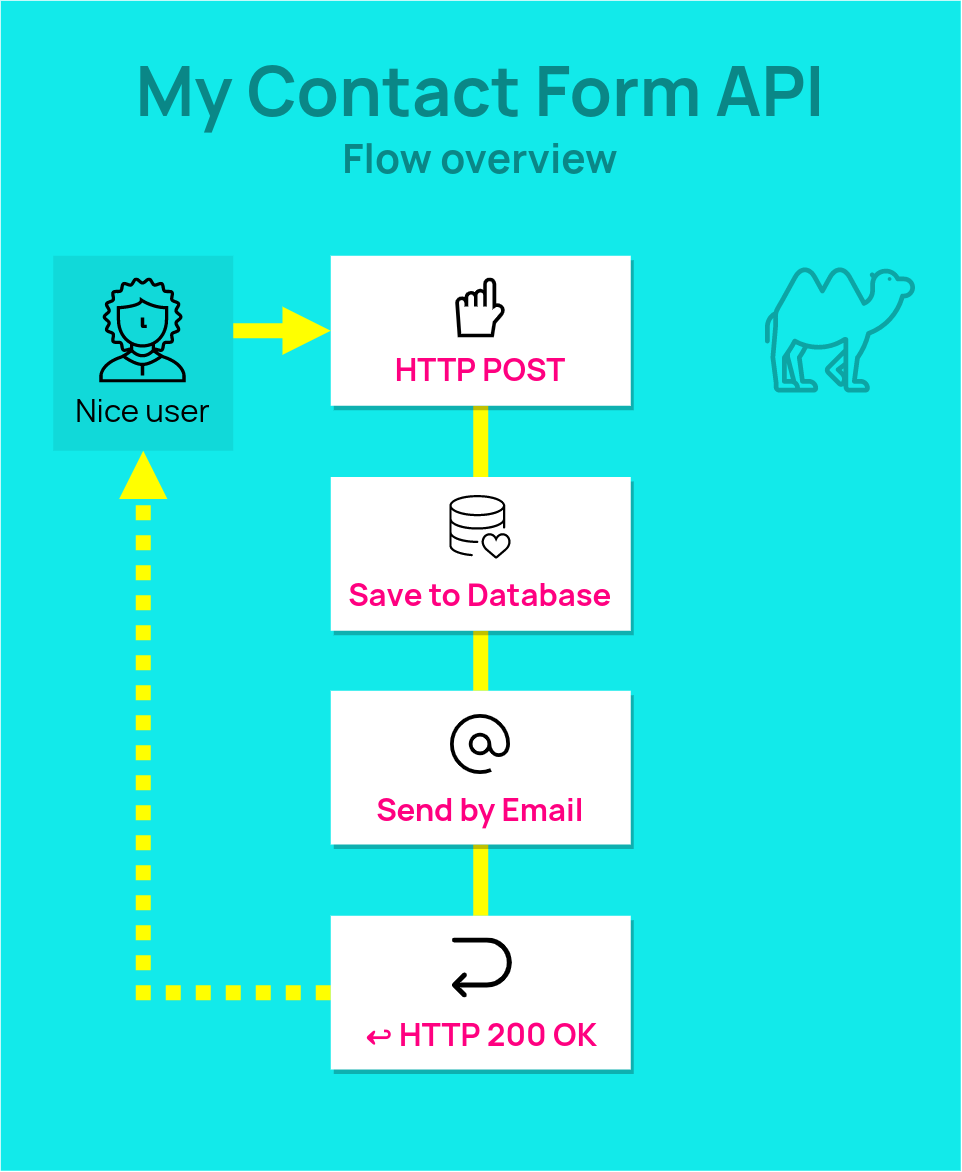
The JavaScript/Lambda backend became… a Spring Boot application.✨
-
The frontend got merged with the backend… to produce a plain old monolith (which I’m calling “POMO”). 🗿✨ (wow monolith)
-
The data moved from the awesome-but-confusing DynamoDB… into PostgreSQL✨, using Spring Data JDBC.
Looking at it now, I can’t believe I didn’t think of it before. I get to build something useful, in a mature and stable ecosystem. Spring gives me the features I need, from database migrations with Flyway, to REST APIs. And it’s not going to change drastically overnight either.
Server-side HTML is just fine
What about the frontend? I’m not building a Netflix microservice. It’s just a CRUD app with some cheap lipstick.
Do I need to separate the frontend and backend, and create a fancy single-page web application? Probably not. (Although I did have fun developing a SPA with Svelte.)
Server-rendered HTML is the boring, old school way to do it. It has fallen out of fashion, but it’s still around. And you can still achieve a lot with it.
In Spring, the modern option for server-rendered HTML is Thymeleaf templates. I’m learning how to do it right with Wim Deblauwe’s excellent Taming Thymeleaf book.
When I want to make a change to a screen in the app, I just change the HTML in the template file. It’s worringly simple.
And I can even make code changes with automatic reload in the browser. Now my web browser reloads the page whenever I change a template.
You’re probably thinking: “But this is all static HTML, it’s not very modern”. Well, that may be true, although I’ll defend my minimal HTML and CSS, to the death, with a tiny sword. But if I need to add a little more sugar to the UI, I can just use htmx. It’s a tiny (~10kb!) JavaScript library for performing simple AJAX requests. It’s the icing on the proverbial cake. And I don’t even need to write any JavaScript.
Make it easy to build and easy to deploy
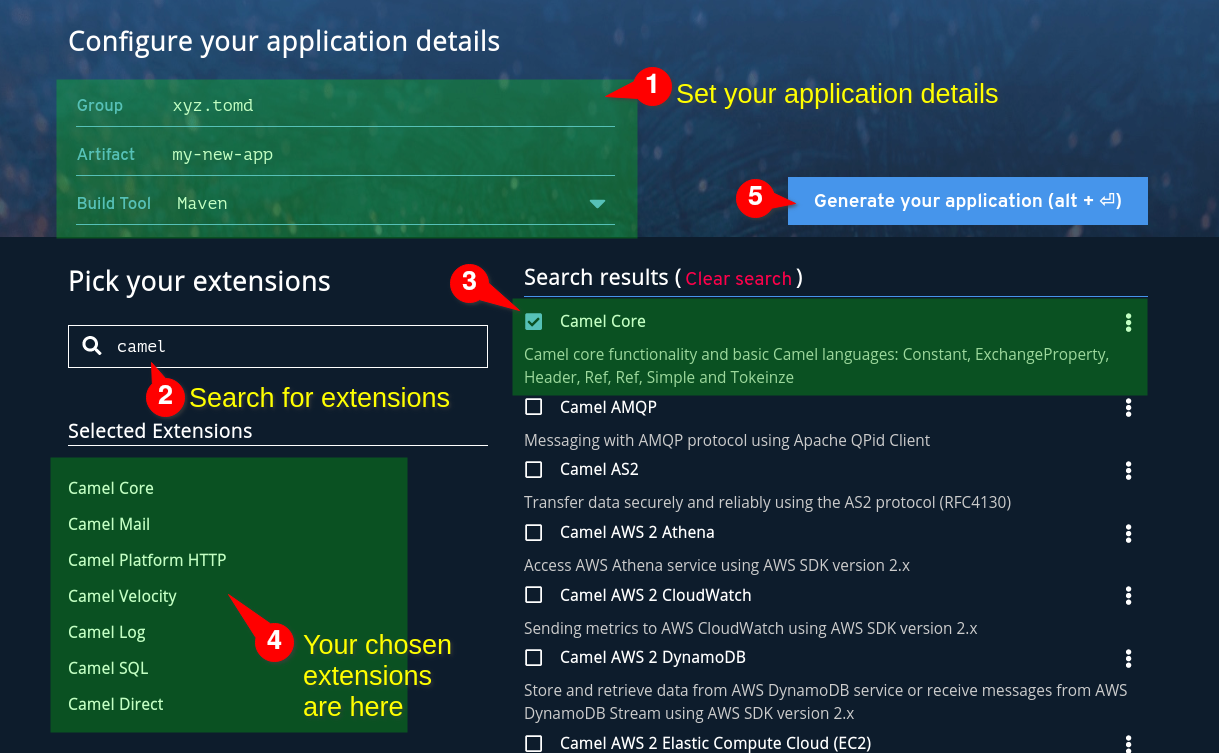
Once I’ve finished developing a new feature, I build a fat-jar by running mvn clean package on my laptop.
When I first started rewriting this app in Java, I thought I needed a CI/CD pipeline. I wasted time pondering where to run the pipeline, and how I would wire it up to my target server.
So I abandoned that. I’m a company of one. I don’t need to add that complexity just yet.
Instead, I just rsync the jar to the server. Ha ha ha. Rsync! People literally point and laugh at me on the street for this. What a simple fool I am.
How does the app run? I thought that I would need to run it in a container. (You can probably guess where this is going..) I spent a lot of time thinking about it, too. Where do I build the image? Should I use a registry? But where can I store private images without paying? Should I use Docker or Podman?
Well, I abandoned all that, too.

A JAR and a database is fine.
So I installed a JRE and a database on the target server. My Linux distribution, CentOS, comes with stable versions of OpenJDK and PostgreSQL in its repositories, so I just use those.
I run everything on a cheap server from Linode or Hetzner (with plenty of capacity for other apps too).
Then I run it on the server using java -jar. Done. Spring Boot runs any database migrations, and it starts the app.
I mean, it’s so laughably simple, and cheap, that you should try it for your next pet project.
]]>