Using environment variables in Jenkins pipelines - with examples
When you’re writing a Jenkins pipeline, sometimes you want to find a way to be able to inject some dynamic values into the pipeline, so that you don’t have to hardcode everything the pipeline.
This is especially useful for things like:
-
runtime configuration for your job
-
additional job parameters which you might only know at runtime, but not at design time
-
sensitive data which should only be injected to the job at runtime, and not hardcoded into the pipeline or Jenkinsfile
-
toggling certain parts of the pipeline - providing a parameter which describes a certain subset of tests you want to run.
-
IDs of any credentials which you might have defined in Jenkins
Dynamic values like these are made available in your pipeline as environment variables. If you carry on reading then in this article I’ll show you how to use them.
Basic usage: setting environment variables manually
So, how do you declare environment variables inside a Jenkins pipeline?
First, you need to initialise your variables. In declarative pipeline syntax, you do this in an environment block in the pipeline definition (Jenkinsfile). You can do this:
-
at the top level, to define environment variables that will be shared across all pipeline stages
-
at the stage level, if you want to define environment variables local to a stage.
Here’s an example of the environment block (for a full example, see further below):
// Set one environment variable named FAVOURITE_FRUIT
environment {
FAVOURITE_FRUIT = 'tomato'
}
Then, to use your variables, use this syntax:
${VARIABLE_NAME}
For example, you might want to use environment variables with the echo step, or the sh step, to pass an environment variable as an argument to a command, e.g.:
// Uses Jenkins's 'echo' step
echo "I like to eat ${FAVOURITE_EGG_TYPE} eggs"
// Runs the shell command 'echo'
sh "echo I like to eat ${FAVOURITE_FRUIT} fruit"
Special built-in Jenkins variables
Jenkins also has a bunch of environment variables which it populates for you by default. This includes information about your job and the specific build which is running.
This means you can access things like the job name and build number inside your pipelines.
These variables are accessed like environment variables, so you can use them in your pipelines. For example, you might want to use the build number as a tag in your Git repository.
Here are some of the most common variables which you can access from your pipelines:
| Variable name | Description | Example value |
|---|---|---|
| JOB_NAME | The name of the job in Jenkins | my-job |
| JOB_URL | The URL to the job in Jenkins UI | http://localhost:8080/job/my-job/ |
| BUILD_NUMBER | The number of the build in Jenkins | 6, 7, etc.. |
| BUILD_TAG | A unique tag for this job name and number | my-job-build-6 |
To use these variables in a pipeline, just reference them in the same way:
${JOB_NAME}
There are tons more built-in environment variables you can use. To see the full list, go to the (not very well-advertised) path /env-vars.html on your Jenkins server.
For example: If you go to http://localhost:8080/env-vars.html/ on a Jenkins installation, you should see a list like this:
Using job parameters as environment variables
If your job also has parameters, then these will be available just like environment variables.
Take this example job, which has one parameter, WORST_THRONES_CHARACTER, with the value of the worst character from Game of Thrones. :)
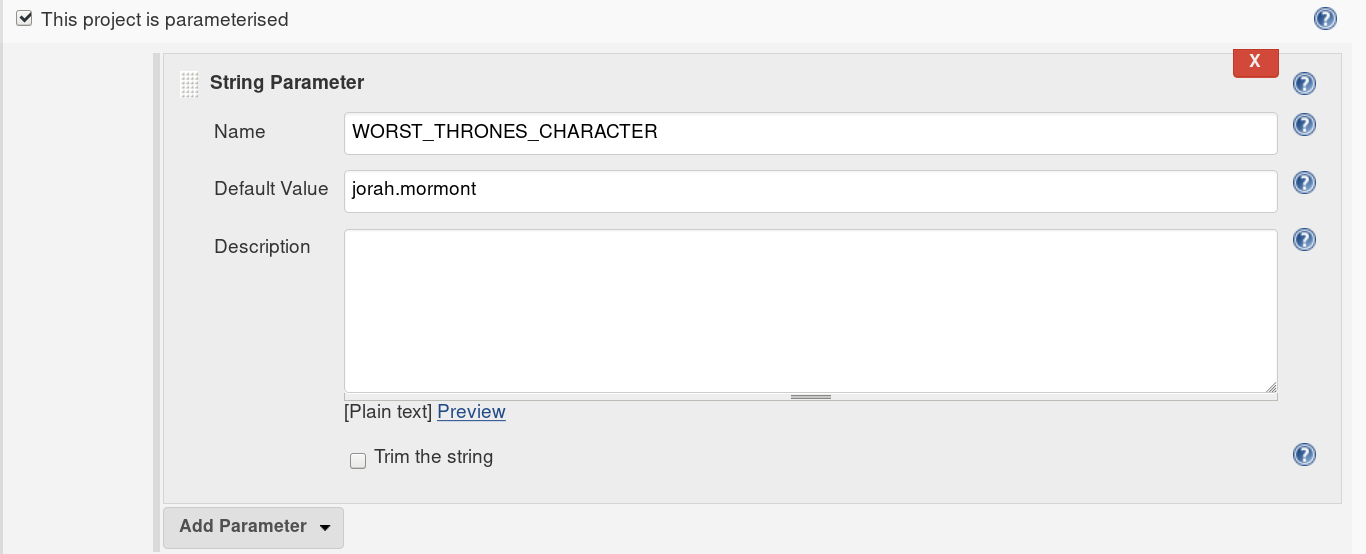
If I want to access this parameter inside my Jenkinsfile, I can refer to it like this:
// Build Parameters are set as environment variables in the shell.
sh "echo The worst GoT character is: ${WORST_THRONES_CHARACTER}"
Setting environment variables from a file
You can also populate environment variables from a file.
You might have a file inside your code repository which contains some configuration properties for your app. Or, you might have a file on a fileshare somewhere.
The Pipeline Utility Steps plugin has a step readProperties which makes it easy to read some properties from a file. You can then use these in your other build steps.
(I generally don’t like to install lots of Jenkins plugins, but this does have a lot of useful steps).
So firstly, install the Pipeline Utility Steps plugin. Then, if you define a properties file in Java .properties format, like this:
WEATHER=rainy
TRAFFIC=heavy
Then you can read in the values from the properties file using the readProperties step, provided by the Pipeline Utility Steps plugin. You’ll also need to copy any variables you want to use into the environment variable scope:
stage('reading from a file') {
steps {
// Here's an example of downloading a properties file
sh 'curl -OL https://raw.githubusercontent.com/monodot/jenkins-demos/master/environment-variables/extravars.properties'
// Use a script block to do custom scripting
script {
def props = readProperties file: 'extravars.properties'
env.WEATHER = props.WEATHER
}
sh "echo The weather is $WEATHER"
}
}
Sharing pipeline variables between stages
If you want to share the same variable between multiple stages of your pipeline, then you just need to define it at the top level of your pipeline.
pipeline {
agent any
environment {
FAVOURITE_FILM = 'The Goonies'
}
stages {
//...
Setting global environment variables
You can also set environment variables which will be passed to all pipeline runs. These are global environment variables. You can add these from the Manage Jenkins screen:
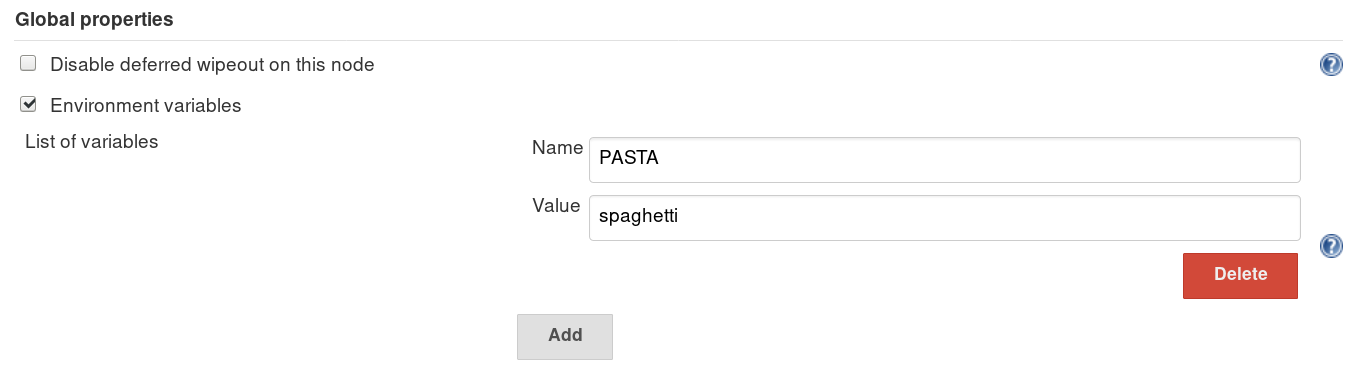
These are set as key-value pairs, and apply for every build that’s run from the master node. Just like above, you use ${key} syntax, so for the example above you’d access the variable using ${PASTA}.
Example - a complete Jenkinsfile with environment variables
Finally, here’s a complete example Jenkins declarative pipeline which uses environment variables, ready for you to copy and start from:
pipeline {
agent any
environment {
FAVOURITE_FRUIT = 'tomato'
}
stages {
stage('echo env vars') {
steps {
// This prints out all environment variables, sorted alphabetically
// You should see the variables declared further below
sh 'printenv | sort'
sh "echo I like to eat ${FAVOURITE_EGG_TYPE} eggs"
sh "echo And I like to drink ${FAVOURITE_DRINK}"
sh "echo My favourite city is ${FAVOURITE_CITY}"
// Build Parameters are also set as environment variables in the shell.
sh "echo The worst GoT character is: ${WORST_THRONES_CHARACTER}"
// We can also access some of the built-in environment variables
sh "echo My hostname is: ${HOSTNAME}"
// Environment variables can be overridden within a certain block
withEnv(['FAVOURITE_CITY=Portland']) {
sh "echo My favourite city is temporarily ${FAVOURITE_CITY}"
}
}
// This block is evaluated before executing the steps block
environment {
FAVOURITE_EGG_TYPE = "poached"
FAVOURITE_DRINK = "sauvignon blanc"
FAVOURITE_CITY = "London"
FAVOURITE_FRUIT = "satsuma"
}
}
stage('second stage') {
steps {
// This will echo tomato, because the env var was set at the global scope
sh 'echo My favourite fruit is ${FAVOURITE_FRUIT}'
}
}
}
}
You can also find this on GitHub! Check out the demo repository at the link below:
See the example repository on GitHub
I hope this has helped you understand how to use variables inside your Jenkins pipelines!
Let me know what you think in the comments below.